Nicolas Martel-Côté1, B.Sc., Lydia Taibi1, candidate au Pharm.D., Juliette Vérot1, candidate au Pharm.D., Anais Daydé1, candidate au Pharm.D., Manon Marc1, candidate au Pharm.D., Mathilde Dupré1, candidate au Pharm.D, Denis Lebel2, B.Pharm., M.Sc., F.C.S.H.P., F.O.P.Q., Jean-François Bussières3,4, B.Pharm., M.Sc., M.B.A., F.C.S.H.P., F.O.P.Q.
1Assistant(e) de recherche au moment de l’étude, Département de pharmacie, unité de recherche en pratique pharmaceutique, Centre hospitalier universitaire Sainte-Justine, Montréal (Québec) Canada;
2Chef, Département de pharmacie, Centre hospitalier universitaire Sainte-Justine, Montréal (Québec) Canada;
3Pharmacien, responsable, Unité de recherche en pratique pharmaceutique, Centre hospitalier universitaire Sainte-Justine, Montréal (Québec) Canada;
4Faculté de pharmacie, Université de Montréal, Montréal, Québec, Canada
Reçu le 12 mars 2024; Accepté après révision le 16 mai 2024
Résumé
Objectif: Décrire le profil général du comportement de deux agents conversationnels et leurs différentes versions existantes et qualifier l’adéquation des réponses proposées à des questions sur les rôles et retombées du pharmacien. Qualifier la justesse des références bibliographiques proposées par ces agents conversationnels.
Méthode: Étude descriptive et qualitative de type transversal exploratoire. Deux agents conversationnels ont été sélectionnés, soit ChatGPT (version 3.5 gratuite, version 4 payante) et Bing (trois versions, soit Bing équilibré, précis et créatif). Quarante-six questions sur les rôles et les retombées de l’activité pharmaceutique ont été formulées. Un panel de trois experts a été formé afin de juger de la justesse des réponses. De plus, la qualité des références a été décrite et évaluée. Seules des statistiques descriptives ont été effectuées.
Résultats: Les deux agents utilisés proposent une proportion très élevée de réponses jugées adéquates par le panel d’experts, soit 95 % (ChatGPT-3.5 et ChatGPT-4), 91 % (Bing équilibré), 98 % (Bing créatif) et 91 % (Bing précis). La proportion de références adéquates varie d’un agent à l’autre, soit 75 % (3/4, ChaptGPT-3.5), 80 % (4/5, ChatGPT-4), 89 % (48/54, Bing équilibré), 91 % (133/146, Bing créatif) et 91 % (91/100, Bing précis).
Conclusion: Cette étude montre que deux agents conversationnels (Chat GPT-3.5, ChatGPT-4, Bing équilibré, précis, créatif) proposent des réponses adéquates à une série de questions entourant les rôles et retombées des pharmaciens. Toutefois, ChatGPT propose un nombre plus limité de références que Bing et parfois des références inadéquates ou inventées. Il apparaît donc nécessaire de continuer d’évaluer l’utilité et la justesse des agents conversationnels en pharmacie.
Mots-clés: agent conversationnel, intelligence artificielle, justesse, réponses, rôles et retombées du pharmacien
Summary
Objective: To describe the general behavioural profile of two chatbots and their different existing versions and to assess the adequacy of proposed answers to questions about the role and impact of pharmacists. To assess the accuracy of the bibliographic references provided by these chatbots.
Method: Descriptive and qualitative exploratory cross-sectional study. Two chatbots were selected: ChatGPT (free version 3.5, paid version 4) and Bing (three versions, namely Bing balanced, precise, and creative). Forty-six questions about the role and impact of pharmacist-led activities were developed. A panel of three experts was formed to assess the accuracy of chatbot answers. In addition, the quality of the references provided by the chatbots was described and evaluated. Descriptive statistics were conducted.
Results: The two chatbots provided a very high proportion of responses deemed adequate by the panel of experts, i.e. 95% (ChatGPT-3.5 and ChatGPT-4), 91% (Balanced Bing), 98% (Creative Bing) and 91% (Precise Bing). The proportion of adequate references varied from one chatbot to another, i.e. 75% (3/4, ChaptGPT-3.5), 80% (4/5, ChatGPT-4), 89% (48/54, Balanced Bing), 91% (133/146, Creative Bing) and 91% (91/100, Precise Bing).
Conclusion: This study shows that two chatbots (Chat GPT-3.5, ChatGPT-4, Bing balanced, precise, creative) provide adequate answers to a series of questions surrounding the role and benefits associated with pharmacist-led activities. However, ChatGPT offers a more limited number of references than Bing and sometimes offers inadequate or invented references. It therefore seems necessary to continue to evaluate the usefulness and accuracy of chatbot use in pharmacy.
Keywords: chatbot, artificial intelligence, accuracy, answers, role and impact of the pharmacist
Le rôle du pharmacien continue d’évoluer partout dans le monde. La pandémie de COVID-19 a contribué à l’élargissement des activités du pharmacien, en permettant notamment l’instauration de certains traitements, la prolongation ou l’ajustement des ordonnances de médicaments ou encore la vaccination des patients1.
Dans la littérature, on mesure cette évolution par un nombre croissant d’articles portant sur les retombées du pharmacien. Par exemple, sur Pubmed, une recherche en texte libre des termes « impact AND pharmacist », donne plus de 1000 publications par année depuis 2021 alors qu’il y en avait cinq fois moins dix ans plus tôt2. Afin de mettre en valeur cette littérature, notre équipe de recherche met à jour périodiquement un site Web recensant les articles scientifiques portant sur les rôles du pharmacien et ses retombées ( https://impactpharmacie.org)3,4. Cette base de données peut être consultée en libre accès tant par les professionnels de la santé que le grand public.
Depuis le lancement de ChatGPT (Chat Generative Pre-trained Transformer, OpenAI, San Francisco, Californie, États-Unis) en novembre 2022, les professionnels de la santé se questionnent sur la place à donner aux agents conversationnels reposant sur l’intelligence artificielle5. Les premiers travaux publiés mettent en évidence des possibilités d’application (p. ex. : aide à la rédaction scientifique, production de réponses efficaces dans un langage simple) et des préoccupations (p. ex. : production de fausses informations ou références, intégrité scientifique et plagiat)6.
Les agents conversationnels sont définis comme des « agents intelligents, intégrant l’intelligence artificielle à diverses fins. Par exemple, un agent conversationnel intelligent peut mettre à profit l’apprentissage d’un grand modèle de langage, lui permettant de prendre en compte une quantité de paramètres pour répondre à une grande variété de requêtes de façon syntaxiquement et sémantiquement correcte »7.
Il existe encore très peu de travaux sur le recours aux agents conversationnels en pharmacie. Ces outils sont notamment employés par les professionnels de la santé ainsi que le grand public pour répondre à une variété de questions. Que racontent-ils sur les rôles du pharmacien et les retombées de l’activité pharmaceutique? Proposent-ils davantage de réponses axées sur les pratiques classiques (p. ex. : distribution et vente de médicaments) ou sur le développement des soins pharmaceutiques? Doit-on s’inquiéter pour l’avenir de l’exercice de la pharmacie?
Fort de notre recherche de la littérature sur les rôles du pharmacien et les retombées de l’activité pharmaceutique, nous nous sommes intéressés à l’utilisation d’agents conversationnels en pharmacie sur ce sujet.
Il s’agit d’une étude descriptive mixte (c.-à-d. qualitative et quantitative) de type transversal exploratoire.
L’objectif principal était de décrire le comportement général des différentes versions des deux agents conversationnels alimentés par l’intelligence artificielle et de qualifier la justesse des réponses à des questions sur les rôles et retombées du pharmacien. L’objectif secondaire était de qualifier la justesse des références bibliographiques obtenues.
Deux agents conversationnels ont été sélectionnés, soit ChatGPT (version 3.5 gratuite, version 4 payante) et Bing (trois versions, soit Bing équilibré, précis et créatif) pour un total de cinq outils8. Ces agents ont été retenus pour leur popularité et leur disponibilité au Canada au moment de l’étude. Bien que ChatGPT-3.5 porte sur des données antérieures à 2021, le grand public est davantage susceptible d’opter pour ce dernier en raison de sa gratuité. Parmi les assistants de recherche ayant participé au projet, deux ont été mandatés pour se familiariser avec ces agents en posant, par exemple, des questions sans lien avec le sujet de l’étude. Par la suite, ils ont engagé la conversation à partir d’une séquence de questions prédéterminées sur les rôles et retombées des pharmaciens. Chaque question était posée de façon indépendante, c’est-à-dire sans demande de précision. Une assistante de recherche (JV) a posé les questions aux deux versions de ChatGPT tandis que l’autre (AD) a interrogé les trois versions de Bing.
Avant d’engager la conversation, l’équipe de recherche a dressé la liste, dans une séance d’échanges, des questions pertinentes à poser aux agents conversationnels. Les questions proposées visaient à décrire les rôles et les retombées des pharmaciens en officine ou en établissement de santé, en tenant compte de certaines affections ou patientèles et en explorant les différences possibles entre la pratique au Canada et en France ou ailleurs dans le monde. Les réponses obtenues devaient ressembler à celles d’un pharmacien ou d’un assistant de recherche du département de pharmacie. Toutes les questions étaient en anglais. Elles ont été révisées, reformulées de façon uniforme (c.-à-d. en privilégiant le même terme pour un élément commun) et organisées du général au spécifique. L’annexe présente la dernière version des questions retenues et leur séquence. Les questions ont été posées aux agents conversationnels en août 2023.
Les réponses fournies ont été saisies dans un document différent par conversation. Trois experts, soit deux pharmaciens (JFB, DL) hospitaliers principaux participant à la conception et à la mise à jour de la plateforme Impact Pharmacie ainsi qu’un assistant de recherche (NMC) travaillant en pharmacovigilance ont été invités à évaluer indépendamment la justesse de chaque réponse pour chacune des versions des deux agents conversationnels. Une réponse était jugée adéquate si elle ne contenait pas de fausseté et qu’elle apportait un élément de contenu utile en phase avec la question posée ou inadéquate. Les évaluations de la justesse des réponses ont été consignées par chacun des trois experts dans un fichier Excel. En présence d’au moins une divergence entre les trois experts, une discussion avait lieu afin d’obtenir un consensus.
Afin de décrire le comportement général des agents conversationnels et de qualifier la justesse des réponses obtenues, nous avons calculé le nombre de mots par conversation pour l’ensemble des questions posées, la proportion et le nombre de réponses écrites sous forme de listes à puces, comprenant une mise en garde sur la validité des informations citées, la proportion et le nombre de réponses par oui ou non aux questions fermées et la proportion et le nombre de réponses jugées adéquates par conversation.
Pour ce qui est des références bibliographiques, nous avons calculé le nombre de références par conversation, le nombre de références citées plus d’une fois par conversation, le type de références proposées (articles scientifiques, sites Web, autres), la capacité de retracer la référence (oui ou non), l’année de publication (avant septembre 2017, de septembre 2017 à ce jour ou non applicable), la qualité scientifique (étude scientifique, autre, non applicable), le nombre/la proportion de références adéquates par rapport à la question posée. De plus, un indice de qualité (de 0 à 5) composite a été accordé à chacune des références. Il comportait cinq critères dichotomiques (conforme ou non) : 1) citation exacte (c.-à-d. libellé et accessibilité), 2) référence récente publiée après septembre 2017, 3) références de type scientifique (étude, revue de littérature ou systématique), 4) référence liée à la question posée, 5) référence pertinente par rapport à la question posée. Par la suite, une note moyenne (± écart type) a été calculée pour chaque conversation pour l’ensemble des références citées.
Afin d’illustrer l’agencement des réponses proposées par agent conversationnel, nous avons sélectionné, dans les réponses fournies à la question 1, en ordre de mention, les termes utilisés pour décrire les rôles du pharmacien. Enfin, nous avons recueilli des observations générales pour chacun des agents et effectué des statistiques descriptives seulement.
Sur les quarante-six questions posées aux deux agents conversationnels sur les cinq conversations, trois questions (nos 12, 21 et 40) ont été exclues de l’analyse en raison de la perte des réponses des agents conversationnels (par erreur de recopie).
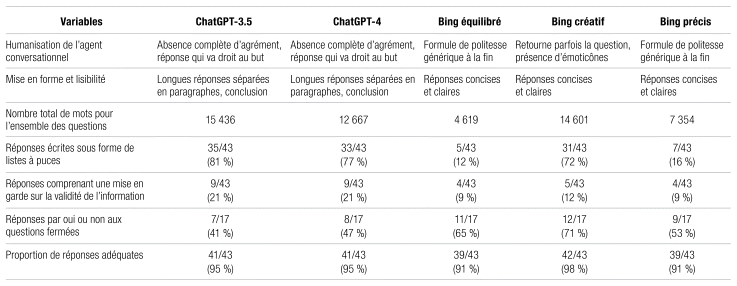
En ce qui concerne le comportement général des agents conversationnels (tableau 1), le nombre total de mots varie beaucoup d’un agent à l’autre (d’un minimum de 4619 mots pour Bing équilibré à un maximum de 15 436 mots pour ChatGPT-3.5). ChatGPT (toutes les versions) offre des réponses plus complètes, mieux structurées, comportant parfois des listes à puces tandis que Bing (équilibré et précis) propose des réponses plus courtes, souvent en un seul bloc, sans énumération ni liste. ChatGPT propose deux fois plus souvent que Bing des mises en garde sur la validité des informations citées. En revanche, Bing propose davantage de réponses courtes (oui ou non) aux questions fermées. Bing et ChatGPT-4 utilisent les données Web en temps quasi réel tandis que ChatGPT-3.5 utilise des données antérieures à septembre 2021.
Pour ce qui est de la justesse des réponses, les deux agents proposent une proportion très élevée de réponses jugées adéquates par le panel d’experts (de 91 % avec Bing équilibré ou précis à 98 % avec Bing créatif).
Les deux versions de ChatGPT ont fourni des réponses inadéquates aux questions 17 et 43. Quant à Bing, les trois versions ont donné des réponses inadéquates à la question 43, deux versions (équilibré et précis) aux questions 25 et 37 et une version (Bing précis) aux questions 33 et 39 (équilibré).
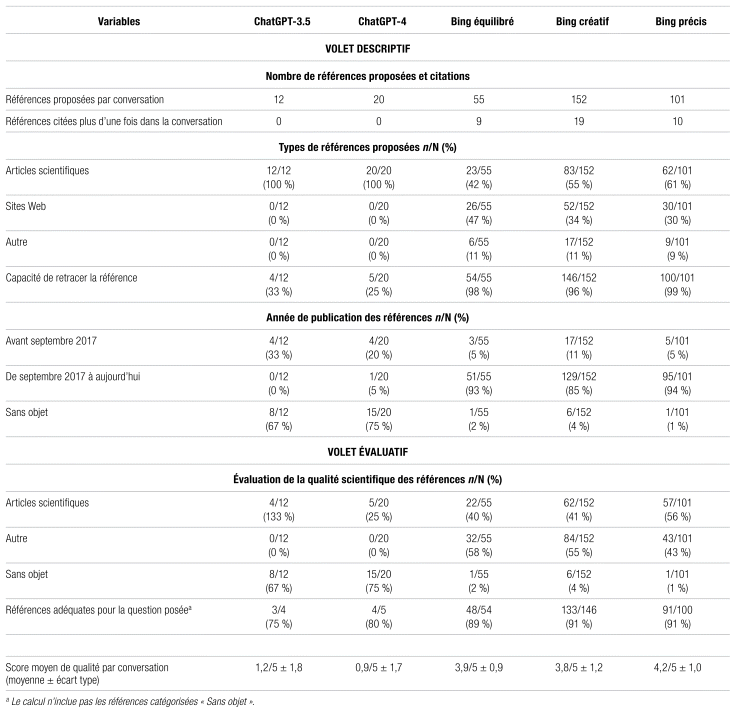
Le nombre de références proposées par conversation varie de 12 à 152 (moyenne de 69 ± 59 références) par conversation. ChatGPT fournit beaucoup moins de références que Bing (16 ± 6 contre 103 ± 49). Il est plus facile de retracer les références avec Bing (de 96 à 99 %) qu’avec ChatGPT (de 25 à 33 %). En outre, le score moyen de qualité est plus élevé avec Bing (de 3,8 à 4,2 sur 5) que ChatGPT (de 0,9 à 1,2). Notons également que Bing répète souvent certaines références (13 ± 6 répétitions en moyenne pour Bing contre aucune pour ChatGPT).
Le tableau 3 présente un profil, en ordre de mention, des rôles du pharmacien donné par chaque agent conversationnel. Comme il s’agit des réponses de chaque agent conversationnel, nous avons conservé les réponses originales, comme pour les questions en annexe.
Cette étude de type exploratoire mixte présente le comportement d’agents conversationnels relatifs aux rôles et retombées de l’activité pharmaceutique. De façon générale, les réponses des agents conversationnels sont adéquates, mais les références proposées pour soutenir les réponses révèlent des problèmes de qualité.
Tableau I Profil général du comportement des agents conversationnels
Le comportement général des agents conversationnels varie tant dans la forme que dans la longueur de la réponse proposée. ChatGPT propose des réponses plus longues que Bing et utilise davantage de listes à puces pour ses énumérations. Il est également plus prudent que Bing en offrant des mises en garde sur certains éléments de réponse. En revanche, ChatGPT répond moins souvent que Bing par oui ou non. Ces observations donnent un aperçu du comportement des agents conversationnels. Il faut toutefois vérifier la justesse des réponses reçues pour apprécier pleinement ces résultats. Notre étude montre ainsi que les deux agents conversationnels proposent des réponses adéquates à la plupart des questions posées sur les rôles et l’influence du pharmacien. Il existe donc un corpus suffisant d’articles sur le Web pour nourrir ces modèles afin qu’ils proposent des réponses crédibles à des questions d’intérêt général. Ainsi, un professionnel, un patient ou un décideur se questionnant sur les rôles et retombées du pharmacien aura un portrait intéressant des tâches possibles de ce dernier. Bien que la plupart des réponses aient été jugées adéquates, il faut noter que les agents conversationnels prennent peu position lorsque les questions visent à établir un rôle, un programme de soins ou une pratique à prioriser par rapport à un autre.
Tableau II Profil descriptif des références proposées par conversation
Bien qu’il n’existe pas d’études semblables à celle-ci, on trouve quelques initiatives sur le recours à des agents conversationnels dans la pratique pharmaceutique. Roosan et coll. ont montré que ChatGPT-4 avait résolu avec précision 39 cas sur 39 en repérant les interactions médicamenteuses, en fournissant des recommandations thérapeutiques et en formulant des plans de gestion généraux sans recommandations spécifiques9. Al-Dujaili et coll. ont observé un taux moyen de réussite de ChatGPT quant à la gestion de cas cliniques dans le temps de 70,8 % à la semaine 1, de 79,2 % à la semaine 2 et de 75 % à la semaine 5. Ce taux comportait des variations plus importantes des réponses des experts internationaux en fonction de leur situation géographique10. Hsu et coll. ont comparé le taux d’exactitude des réponses données par ChatGPT et par un panel d’experts à des questions portant sur les interactions entre les médicaments et les remèdes traditionnels chinois11. Le taux de pertinence des réponses de ChatGPT à 80 questions réelles sur les médicaments, choisies de façon aléatoire, était plus élevé que celui du panel d’experts hospitaliers (61 % contre 39 %). Al-Ashwal et coll. ont observé que Bing avait une plus grande précision et spécificité que Bard, ChatGPT-3.5 et ChatGPT-4 comparativement à un moteur d’analyse d’interactions médicamenteuses12. Enfin, Fournier et coll. ont observé un taux de réponse adéquate plus faible que dans la plupart des études, variant de 30 à 57 % (taux moyen de 44 %) pour un choix de questions adressées à des pharmaciens par le personnel soignant et inscrites dans une base de données13. Ainsi, la performance des agents conversationnels varie selon le thème et la nature des questions posées. Ces données montrent une utilisation émergente des agents conversationnels en pharmacie. D’autres travaux devraient toutefois être menés sur les rôles et retombées de l’activité du pharmacien et de l’équipe technique.
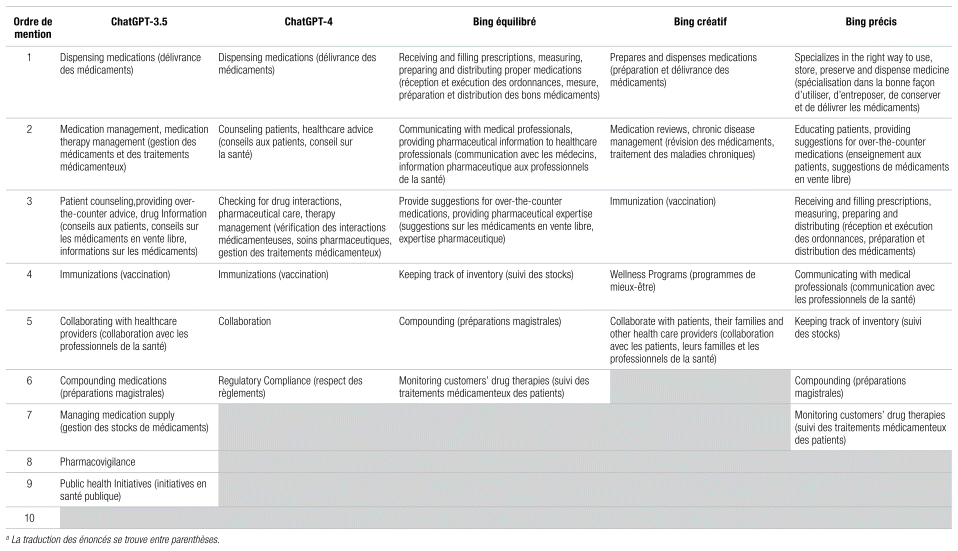
Tableau III Profil des rôles du pharmacien donnés par chaque agent conversationnel en ordre de mentiona
La justesse des références bibliographiques proposées par Bing surpasse largement celle de ChatGPT. Ainsi, on note un nombre plus élevé de références (de 55 à 152 pour Bing contre 12 à 20 pour ChatGPT). Outre la quantité, les références proposées par Bing sont plus récentes et plus adéquates (de 89 à 91 % contre 75 à 80 %). De plus, la note moyenne de qualité par conversation est plus élevée avec Bing (de 3,8 à 4,2 sur 5 selon la version) qu’avec ChatGPT (de 0,9 à 1,2 sur 5 selon la version). L’agent conversationnel invente parfois des références en regroupant différentes informations provenant d’éléments véridiques (p. ex. : auteurs travaillant dans le domaine, mention de revues pertinentes), créant ainsi des références bibliographiques qui peuvent tromper l’utilisateur14,15.
Une analyse des rôles du pharmacien en ordre de première mention par agent conversationnel est intéressante. Bien que tous les agents proposent en première mention un rôle associé à la délivrance des médicaments, dès la deuxième mention, on observe un tri différent. Ainsi, ChatGPT-3.5 et Bing équilibré proposent un rôle lié à la gestion du traitement médicamenteux tandis que les trois autres mentionnent l’éducation thérapeutique. Trois agents conversationnels évoquent un rôle en vaccination et un seul nomme la pharmacovigilance comme rôle du pharmacien. Il est étonnant de constater que les deux versions de ChatGPT ou les trois versions de Bing ne proposent pas le même ordre, étant donné que toutes les questions ont été posées durant la même période. Une évolution des données utilisées par les agents ne peut expliquer cette divergence de hiérarchisation.
Par ailleurs, en considérant tous ces rôles, on obtient un profil détaillé et crédible de la contribution du pharmacien dans la société.
Notre étude nous amène à constater que ces outils semblent incontournables en pharmacie, notamment parce que les étudiants, les collègues et les patients les utiliseront, peu importe les consignes, afin de répondre à des questions de curiosité, d’apprentissage ou pour résoudre un problème ou une situation donnée. Dans le cadre de leur pratique et pour leurs besoins personnels, les pharmaciens devraient, par conséquent, être exposés dès le début de leur formation à ces outils afin d’en découvrir les avantages et les limites selon le contexte et leur pratique. Kleebayoon et coll. notent que l’utilisation de ces agents conversationnels n’est pas sans risque et qu’il faut donc l’encadrer16. Toutefois, dans une revue narrative, Abdel-Aziz et coll. mentionnent qu’il existe encore très peu d’études dans la littérature sur l’emploi de l’intelligence artificielle dans les programmes de formation en pharmacie17. Ainsi, les cliniciens et les enseignants en pharmacie devraient discuter du recours à ces outils dans un cadre pédagogique.
Depuis notre étude, des nouveautés ont été annoncées concernant ces agents. En effet, depuis mai 2024, ChatGPT-4o intègre la lecture d’images ainsi que de contenus sonores et vidéo. Meta a lancé un agent conversationnel ( Meta.ai ) intégré notamment à Facebook et à Instagram. Quant à Microsoft, elle a rendu disponible son outil nommé Copilot. Google, pour sa part, intégrera prochainement son outil Gemini à son moteur de recherche. De plus, il existe une panoplie d’outils d’intelligence artificielle sur le marché, comme l’interface Poe ( https://poe.com ) qui offre un portail intégrant de nombreux outils.
Cette étude comporte des limites. Par exemple, l’échantillon de questions était relativement petit (46 questions) et portait sur un ensemble de sujets d’intérêt général. Une autre étude, comportant une séquence de questions plus spécifiques, pourrait donner des résultats différents. Le panel d’experts ne comportait que trois personnes : deux pharmaciens et un assistant de recherche ayant peu d’expérience avec les agents conversationnels. Un panel d’experts élargi pourrait aussi mener à un taux de justesse différent.
Compte tenu de l’évolution rapide de ce domaine, les réponses recueillies demeurent valides pour la période de l’étude et reflètent les versions offertes en août 2023. Le contenu des réponses peut évoluer dans le temps. Toutefois, le partage de cette expérience nous paraît très utile pour inciter les pharmaciens à s’intéresser aux agents conversationnels.
Cette étude descriptive et qualitative de type transversal exploratoire montre que deux agents conversationnels et leurs versions respectives (Chat GPT-3.5, ChatGPT-4, Bing équilibré, précis, créatif) proposent des réponses adéquates à une série de questions sur les rôles et retombées des pharmaciens. Toutefois, ChatGPT propose un nombre plus limité de références que Bing, et la majorité de ces références sont inadéquates ou inventées. Il apparaît nécessaire de continuer d’évaluer l’utilité et la justesse des agents conversationnels en pharmacie. En raison de l’évolution rapide de ces outils, il est important de se familiariser avec eux, de se tenir à jour, de repérer les possibilités en pratique pharmaceutique, tant dans le cadre de la formation que de l’exercice professionnel. Des études diverses devraient être menées afin de vérifier la justesse des réponses proposées par l’intelligence artificielle et leur influence dans l’exercice de la pharmacie.
Cet article comporte une annexe qui se trouve sur le site de Pharmactuel (www.pharmactuel.com).
Les auteurs n’ont déclaré aucun financement lié au présent article.
Tous les auteurs ont soumis le formulaire de l’ICMJE sur la divulgation de conflits d’intérêts potentiels. Jean-François Bussières est membre du comité de rédaction de Pharmactuel. Les autres auteurs n’ont déclaré aucun conflit d’intérêts lié au présent article.
1. Santos YS, de Souza Ferreira D, de Oliveira Silva ABM, da Silva Nunes CF, de Souza Oliveira SA, da Silva DT. Global overview of pharmacist and community pharmacy actions to address COVID-19: A scoping review. Explor Res Clin Soc Pharm 2023;10:100261.

2. National Library of Medicine. [en ligne] https://pubmed.ncbi.nlm.nih.gov/?term=pharmacist+AND+impact (site visité le 15 mai 2024).
3. Guérin A, Lebel D, Bussières JF. Evidence for the role and impact of pharmacists: description of a website. Can Pharm J (Ott) 2015;73:229–38.
4. Monnier A, Jacolin C, Martel-Côté N, Côté-Sergerie C, Bussières JF. On a besoin d’un pharmacien plus que jamais… en êtes-vous convaincus ? Le pharmacien clinicien 2023;58: 370–71.

5. Eysenbach G. The role of ChatGPT, generative language models, and artificial intelligence in medical education: a conversation with ChatGPT and a call for papers. JMIR Med Educ 2023;9:e46885.
6. Dave T, Athaluri SA, Singh S. ChatGPT in medicine: an overview of its applications, advantages, limitations, future prospects, and ethical considerations. Front Artif Intell 2023; 6:1169595.
7. Agent conversationnel. [en ligne] https://vitrinelinguistique.oqlf.gouv.qc.ca/fiche-gdt/fiche/26545036/agent-conversationnel (site visité le 11 février 2025).
8. Open AI. ChatGPT. Differences between GPT-3.5 et GPT-4. [en ligne] https://chatgpt.ch/en/differences-between-gpt-3-5-and-gpt-4/ (site visité le 15 mai 2024).
9. Roosan D, Padua P, Khan R, Khan H, Verzosa C, Wu Y. Effectiveness of ChatGPT in clinical pharmacy and the role of artificial intelligence in medication therapy management. J Am Pharm Assoc (2003). 2024;64:422–28.e8.
10. Al-Dujaili Z, Omari S, Pillai J, Al Faraj A. Assessing the accuracy and consistency of ChatGPT in clinical pharmacy management: a preliminary analysis with clinical pharmacy experts worldwide. Res Social Adm Pharm 2023;19:1590–4.
11. Hsu HY, Hsu KC, Hou SY, Wu CL, Hsieh YW, Cheng YD. Examining real-world medication consultations and drug-herb interactions: ChatGPT performance evaluation. JMIR Med Educ 2023 Aug 21;9:e48433.
12. Al-Ashwal FY, Zawiah M, Gharaibeh L, Abu-Farha R, Bitar AN. Evaluating the sensitivity, specificity, and accuracy of ChatGPT-3.5, ChatGPT-4, Bing AI, and Bard against conventional drug-drug interactions clinical tools. Drug Healthcare Patient Saf 2023;15:137–47.
13. Fournier A, Fallet C, Sadeghipour F, Perrottet N. Assessing the applicability and appropriateness of ChatGPT in answering clinical pharmacy questions. Ann Pharm Fr 2024;82:507–13.
14. Jeyaraman M, Ramasubramanian S, Balaji S, Jeyaraman N, Nallakumarasamy A, Sharma S. ChatGPT in action: harnessing artificial intelligence potential and addressing ethical challenges in medicine, education, and scientific research. World J Methodol 2023;13:170–8.
15. Wagner MW, Ertl-Wagner BB. Accuracy of information and references using ChatGPT-3 for retrieval of clinical radiological information. Can Assoc Radiol J 2024;75:69–73.
16. Kleebayoon A, Wiwanitkit V. Performance and risks of ChatGPT used in drug information: comment. Eur J Hosp Pharm 2023;31:85–6.
17. Abdel Aziz MH, Rowe C, Southwood R, Nogid A, Berman S, Gustafson K. A scoping review of artificial intelligence within pharmacy education. Am J Pharm Educ 2024;88 :100615.
Pour toute correspondance : Jean-François Bussières, CHU Sainte-Justine, 3175, chemin de la Côte-Sainte-Catherine, Montréal (Québec) H3T 1C5, Canada; Téléphone : 514 345-4603; Courriel : jean-francois.bussieres.hsj@ssss.gouv.qc.ca
PHARMACTUEL, Vol. 58, No. 1, 2025